Tutorial
Example usages of CMPlot, with plots and options used are presented below (e.g. Heights in families).
An introduction to the several features is also offered by the provided jupyter notebook. This can be previewed via nbviewer.jupyter.org, or directly edited and run locally.
Hands-on
In fact probably the best way to try out the several features of cmplot is to clone from github,
or to directly download the Julia or
the Python jupyter notebook and play with it,
tweaking options, trying different data combinations and expecially using your own data
or other publicly available datasets.
The notebook examples use the datasets from Iris [Anderson_Edgar_Fisher_1935_1936] and Wages [Cornwell_Rupert_1988] but it is immediate to switch to other datasets via the included calls to RDatasets - for Julia - and PyDatasets - for Python).
Heights in families
For this example we’ll use the dataset from Galton on the heights of parents and their children [Galton_1886].
His data consists of the heights of 930 adult children and of their respective parentages, for a total of 205 families.
>>> import plotly.graph_objects as go
>>> from cmplot import cmplot
>>> from pydataset import data
>>> df = data("GaltonFamilies")
With a simple initial plot we can see that all males (sons and all fathers) occupy a very similar range of heights and all females (daughters and all mothers) likewise, and with very similar distribution:
>>> cmplot(df, xcol="gender", ycol=["father", "childHeight", "mother"], pointsoverdens=True, pointshapes=["line-nw", "line-ne", "line-ew"])
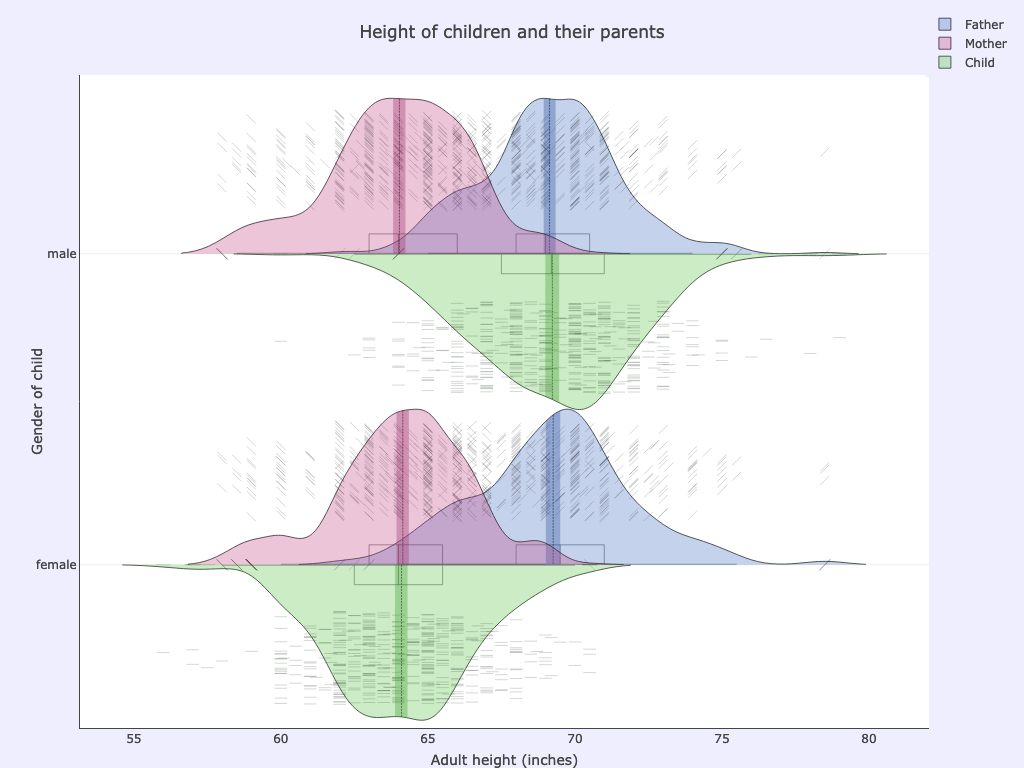
xcol: gender
ycol: father, childHeight, mother
Options used:
pointsoverdens= True,pointshapes= [“line-nw”, “line-ne”, “line-ew”]
Sometimes a boxplot or even a violinplot can be less informative or harder to decode than a simple histogram as shown in the top part of the next picture:
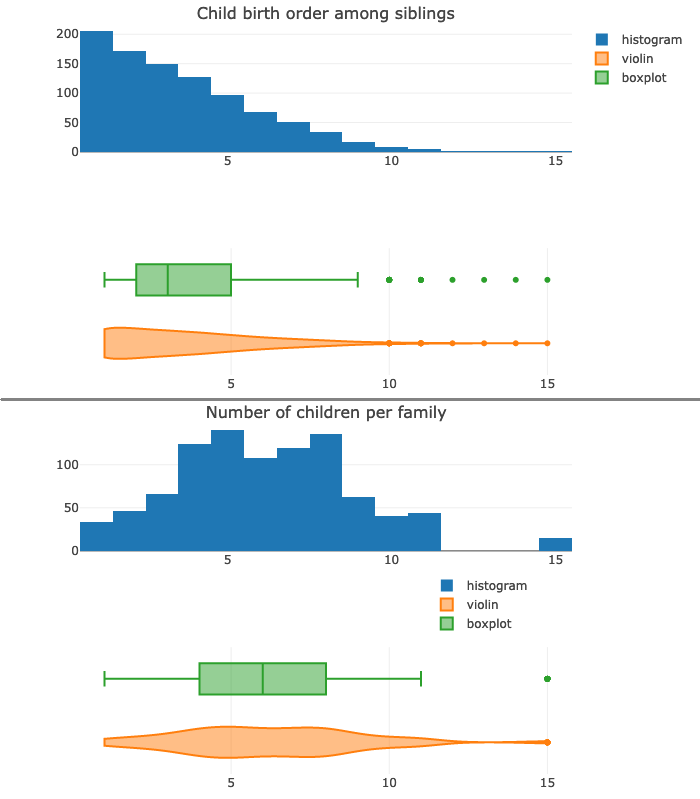
Furthermore the boxplot also suffers from a very well known drawback: it hides any multimodal distribution (the two peaks - modes - at 5 and 8 number of children per family; as seen in the bottom half of the picture).
Showing the raw data alongside the kernel density curve helps in seeing things more clearly:
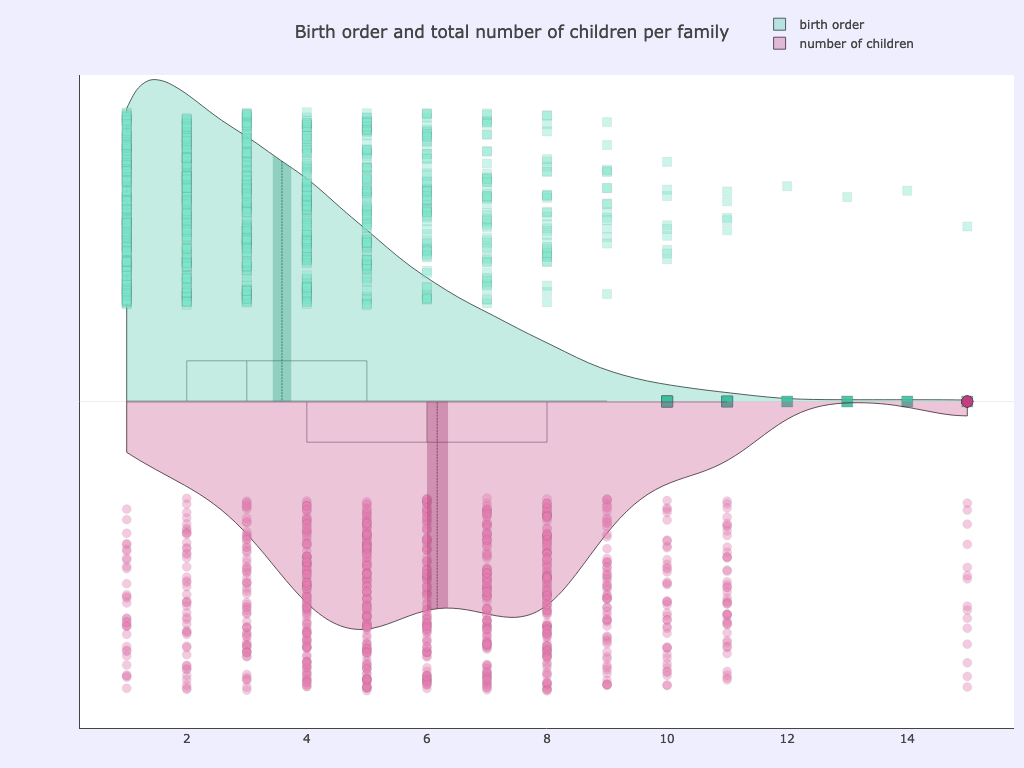
ycol: childNum, children
Options used:
pointsoverdens= True,spanmode= ‘hard’
After binning the total number of siblings in a family and the birth order (which child is born earlier or later), we can further explore the data.
For example plotting child height vs family size we can see a lower average height for children of very numerous families (with 9 or more siblings):
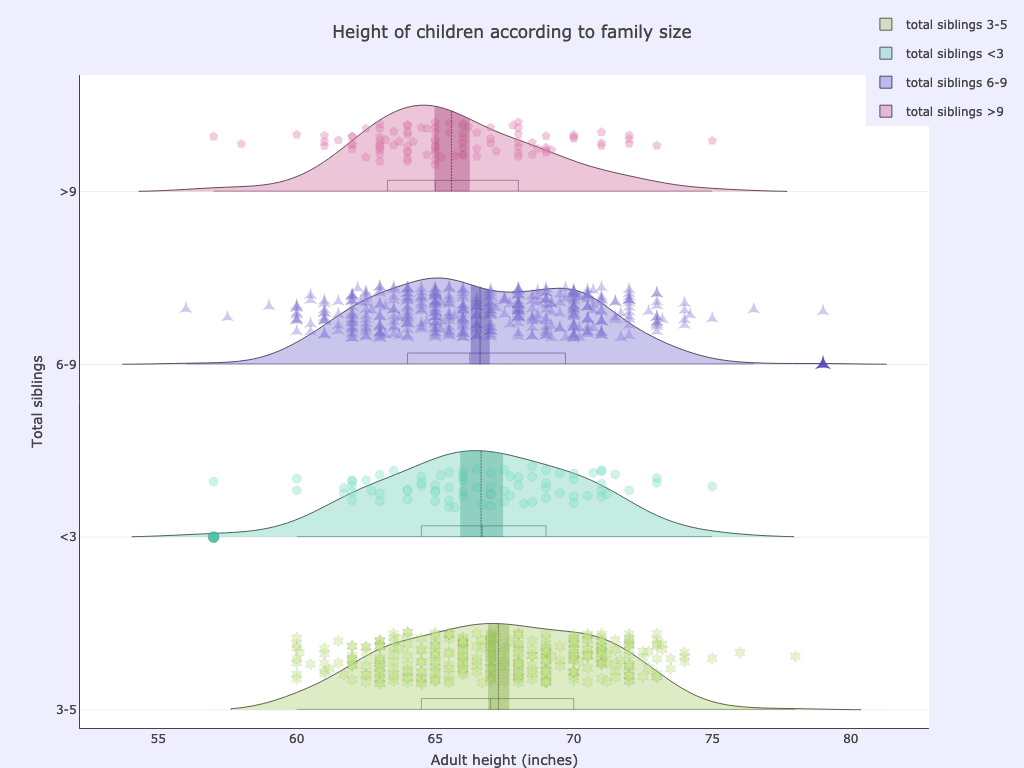
xcol: childrenBinned
ycol: childHeight
Options used:
pointsoverdens= True,side= ‘pos’,ycolorgroups= False
Being born late in the family was apparently even less conducive to stature: there is much lower average height for late born children compared to earlier born ones (Note that binning on birth order in this dataset needs to be adjusted to factor for gender due to how the birth order was originally recorded):
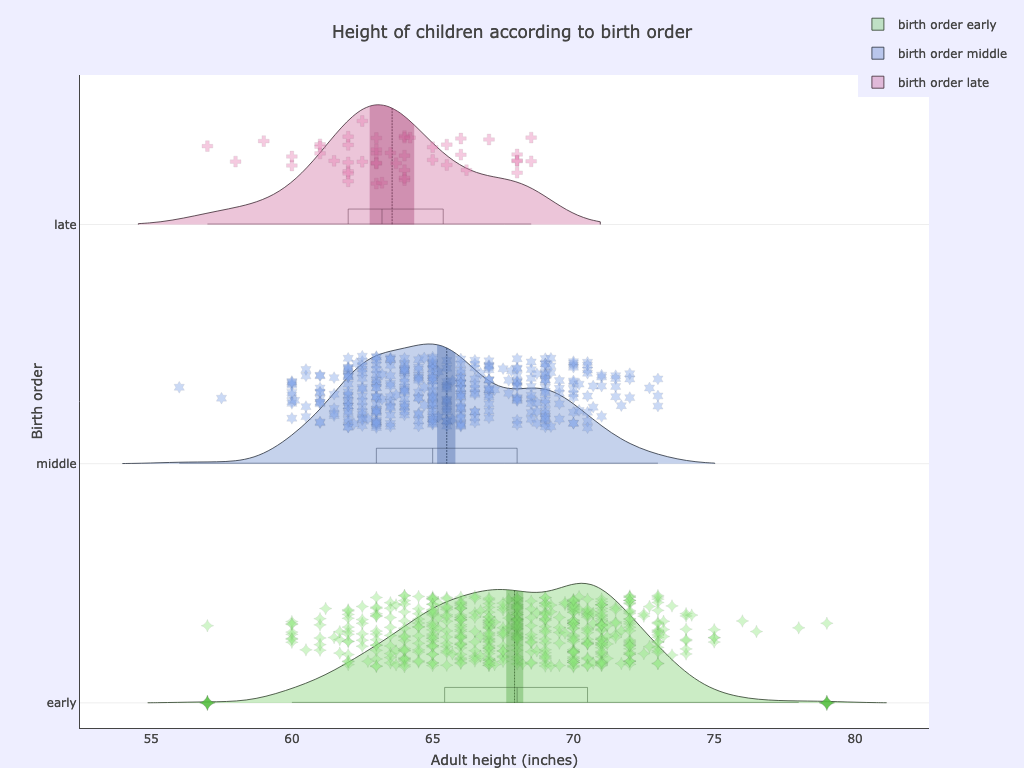
xcol: childNumBinned
ycol: childHeight
Options used:
pointsoverdens= True,side= ‘pos’,ycolorgroups= False
Cloudy Mountain Plots make it is easy to separate according to combinations of two or more categorical variables. For example we can plot children’s height according to both their gender and their birth order:
>>> cmplot(df, xcol=["childNumBinned", "gender"], ycol="childHeight", ycolorgroups=False, xsuperimposed=True)
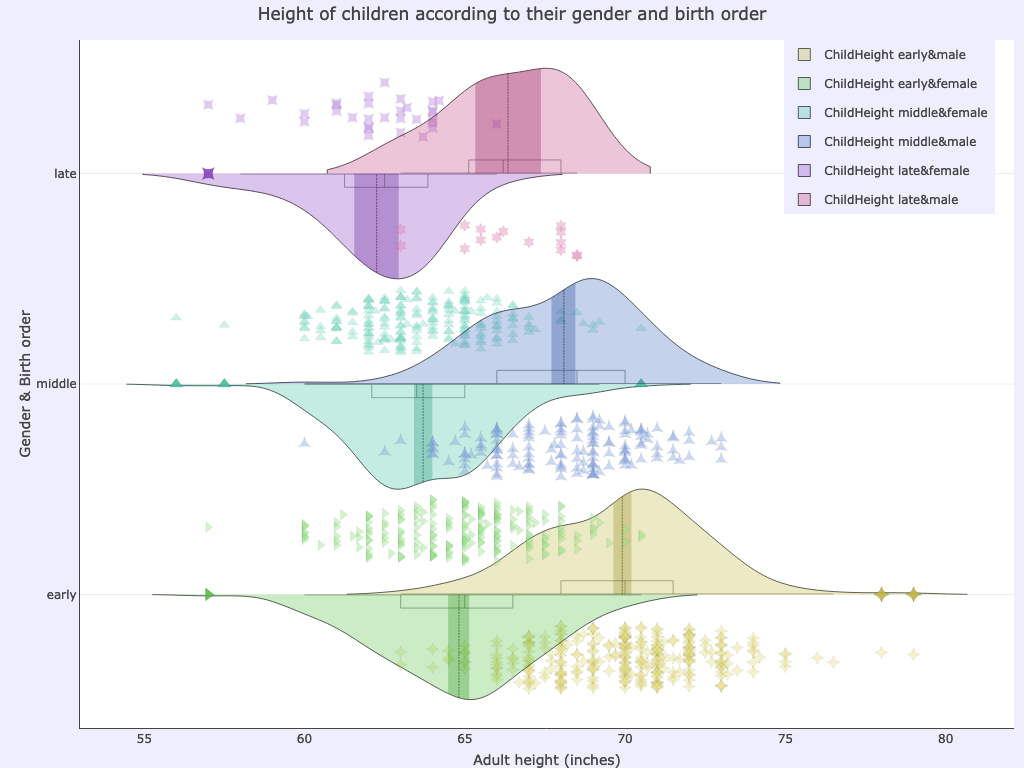
xcol: childNumBinned, gender
ycol: childHeight
Options used:
side= ‘pos’,ycolorgroups= False,xsuperimposed= True,
The gender component is obviously the dominant one, but still the plot makes very obvious that children born later than their siblings are on average smaller than those born earlier.
We can also plot the height of parents and of their children according to birth order among siblings.
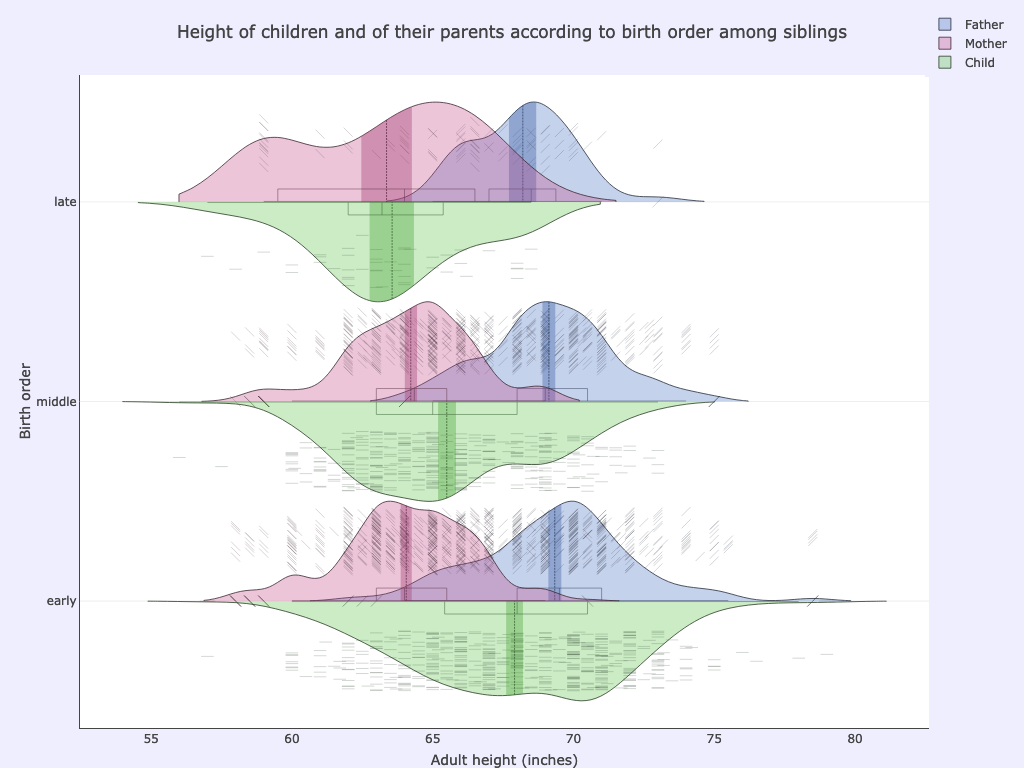
xcol: childNumBinned
ycol: father, childHeight, mother
Options used:
pointsoverdens= True,pointshapes= [“line-nw”, “line-ne”, “line-ew”]
Separating by gender as well as birth order shows that, for the late born, sons are on average shorter than their fathers and daughters shorter than their mothers; for early born ones the situation is reversed, with - on average - sons taller than fathers and daughters taller than mothers:
>>> cmplot(df, xcol=["childNumBinned", "gender"], ycol=["childHeight", "mother"], ycolorgroups=False, xsuperimposed=True)
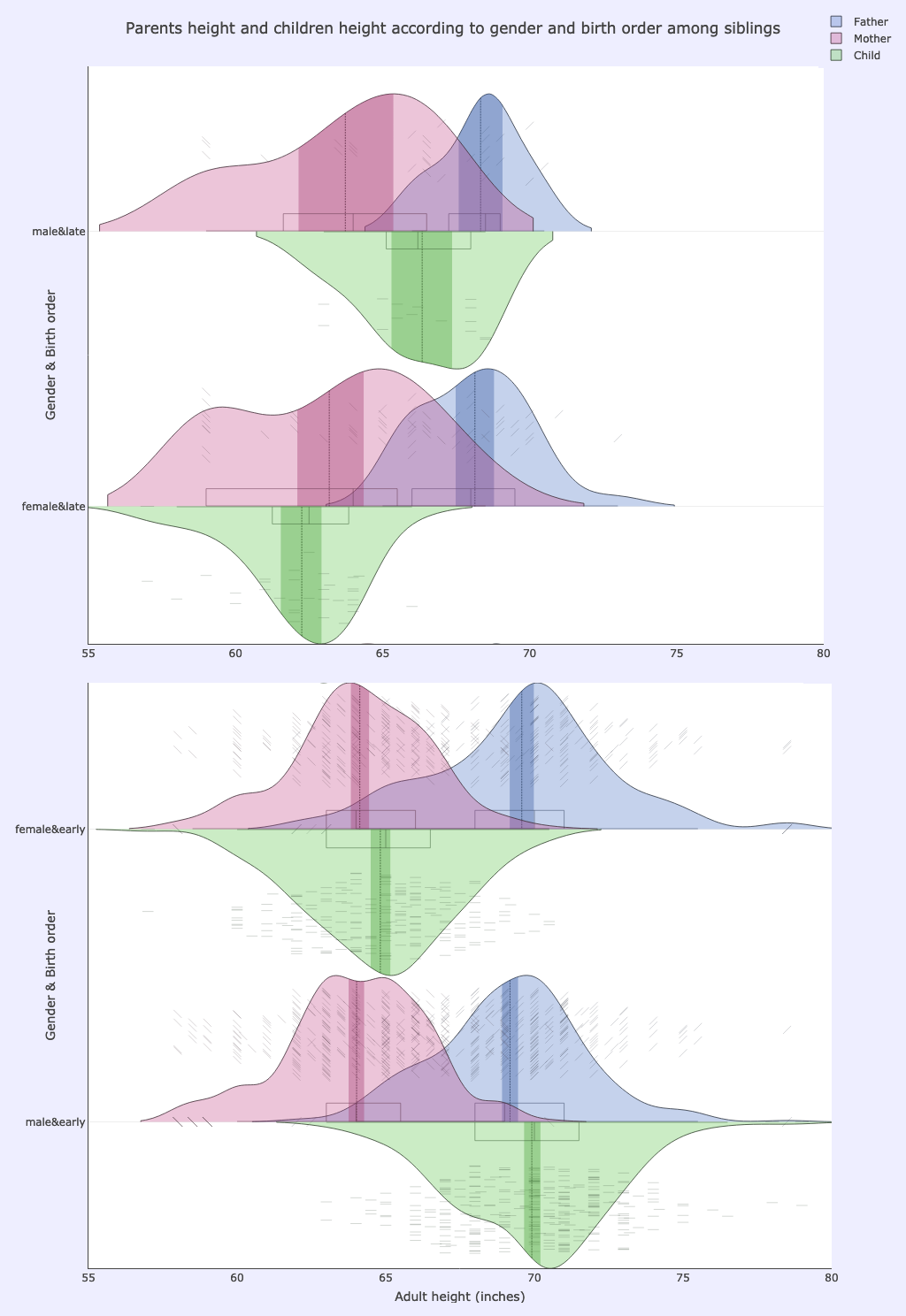
xcol: childNumBinned, gender
ycol: father, childHeight, mother
Options used:
pointsoverdens= True,pointshapes= [“line-nw”, “line-ne”, “line-ew”]
Note how the plotted clouds of raw data points caution us that there is much less data (much sparser data point clouds) for the late born, as these are the children belonging to very numerous families, which are less abundant than the smaller families.
Still the trend is there and the plot is informative and helps us to dig into the data and to make relevant information surface.